

What Is Spatial Jitter?
3D data in Speckle comes in all shapes and sizes (ranging from 1mm to 100km) and at various distances from the “world” origin of (0, 0, 0). Most authoring software have dedicated display pipelines that handle this - to multiple degrees of success and with apparent limitations (one can’t model stuff on the Moon 😅).
When rendering things in a web browser, our go-to WebGL library, Three.js, does not handle this very gracefully: we get display artifacts that we lovingly call “the need for speed” effect, more commonly referred to as spatial jitter. This problem was most evident in models coming from civil engineers - road sections, railways, etc. - or GIS- positioned elements (which tend to be quite far from the infamous Null Island). 📍
::: tip ✨ As the numbers get larger, the precision gets smaller.
:::
Why Does Spatial Jitter Occur?
Numbers in floating point format represent positions in 3D space. With WebGL, we are restricted to use the single-precision floating point format. Later graphics APIs allow for double-precision, but regardless, all floating point formats are an approximation. As the numbers get larger, the precision gets smaller (check out the table here). This behavior of the floating point formats is the root cause of spatial jitter.
For example, if you have some vertices thousands of kilometers away from the origin, and your world units are in meters, the GPU will be doing math with large floating point numbers. Consequently, when you project those vertices on the screen, you will get erratic results from one frame to the next because of the low precision of large value floating point numbers. Such will result in the image jittering, hence the term spatial jitter. This will get worse as your camera gets closer to the rendered objects since it will take up a larger portion of the screen, meaning you will need more precision to get accurate and stable projection results, but that precision wouldn't exist.
The Solution?
We tried to tackle this issue, with inspiration from this article, with two different approaches: RTC and RTE. 💡
The Relative to Centre Approach (RTC)
This approach works fine up to a certain world size. If we want to go larger, we need something else. Additionally, RTC does not fit well with Speckle's future plans for the viewer: changing the batching system completely and batching together geometries aggressively.
An RTC implementation requires the position attributes for the vertices to be defined in the mesh’s local origin. This works well because all one needs, to bring back the geometry in the original world space, is a simple transformation. However, because we’ll be batching geometries, we won’t be able to use any additional transformation to bring them into the original world space. Finding the batch’s center of mass, and baking the positions in relation to that could make this work - but that’s a complication we neither want nor need.
The Relative to Eye Approach (RTE)
Next, we turn towards RTE, also known as the floating origin technique. With RTE, one does not need to alter the original vertex positions in any way. Instead, you consider the viewer (camera) as the stationary origin of space, and everything else moves around it. Unity uses this approach to render large worlds. In essence, what RTE does, is reduce the size of the numbers involved in the typical GPU transformation pipeline when the camera is relatively close to the affected (by jitter) meshes. When the camera is far away, the numbers are again large and one would expect the geometry to jitter, but here’s the catch: when the camera is far away, the projection of the mesh on the screen is much smaller, this means the inherent precision you need is also much smaller, hence, no more jittering.
Case Study
Here’s how the jitter problem originally manifested itself:
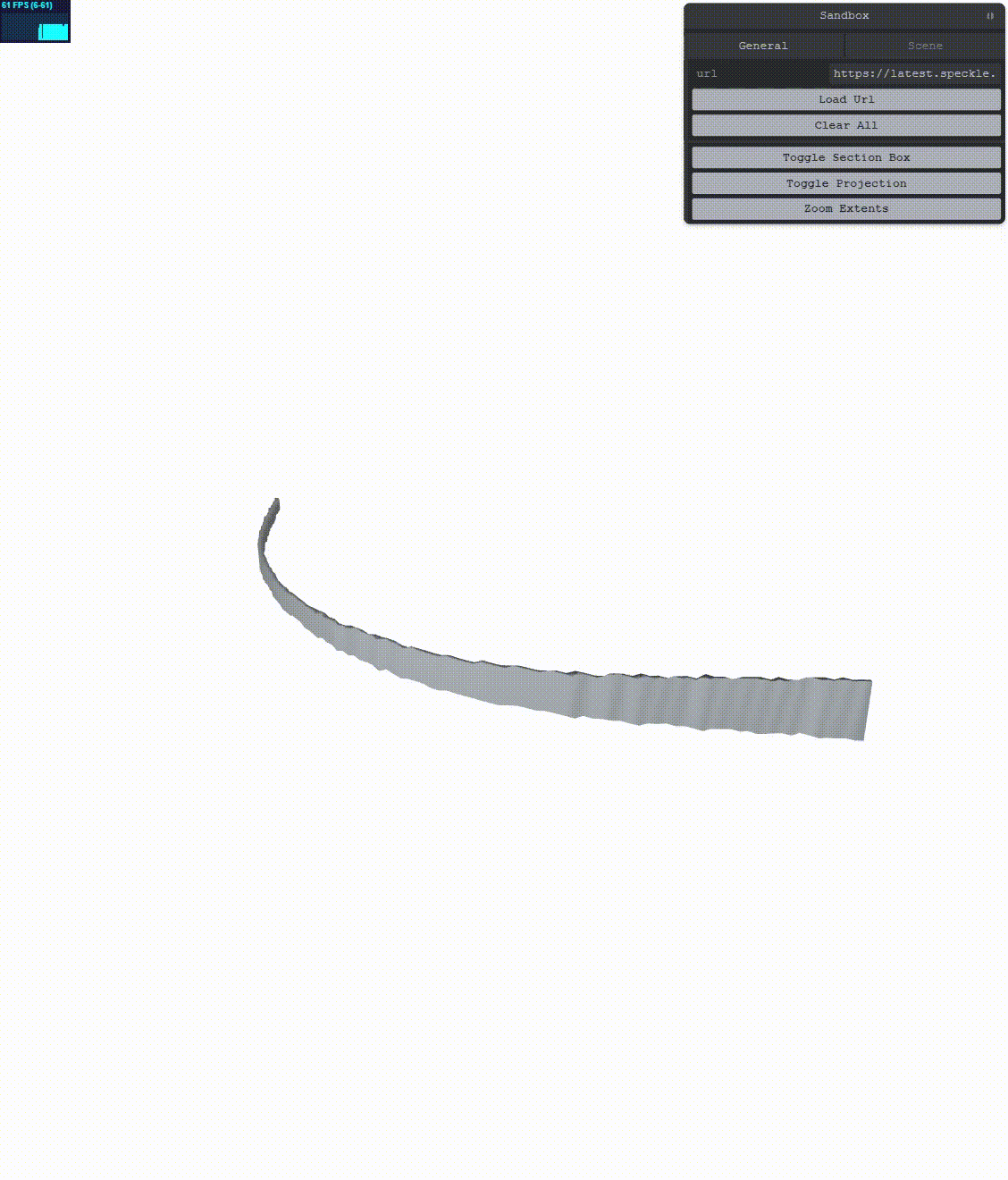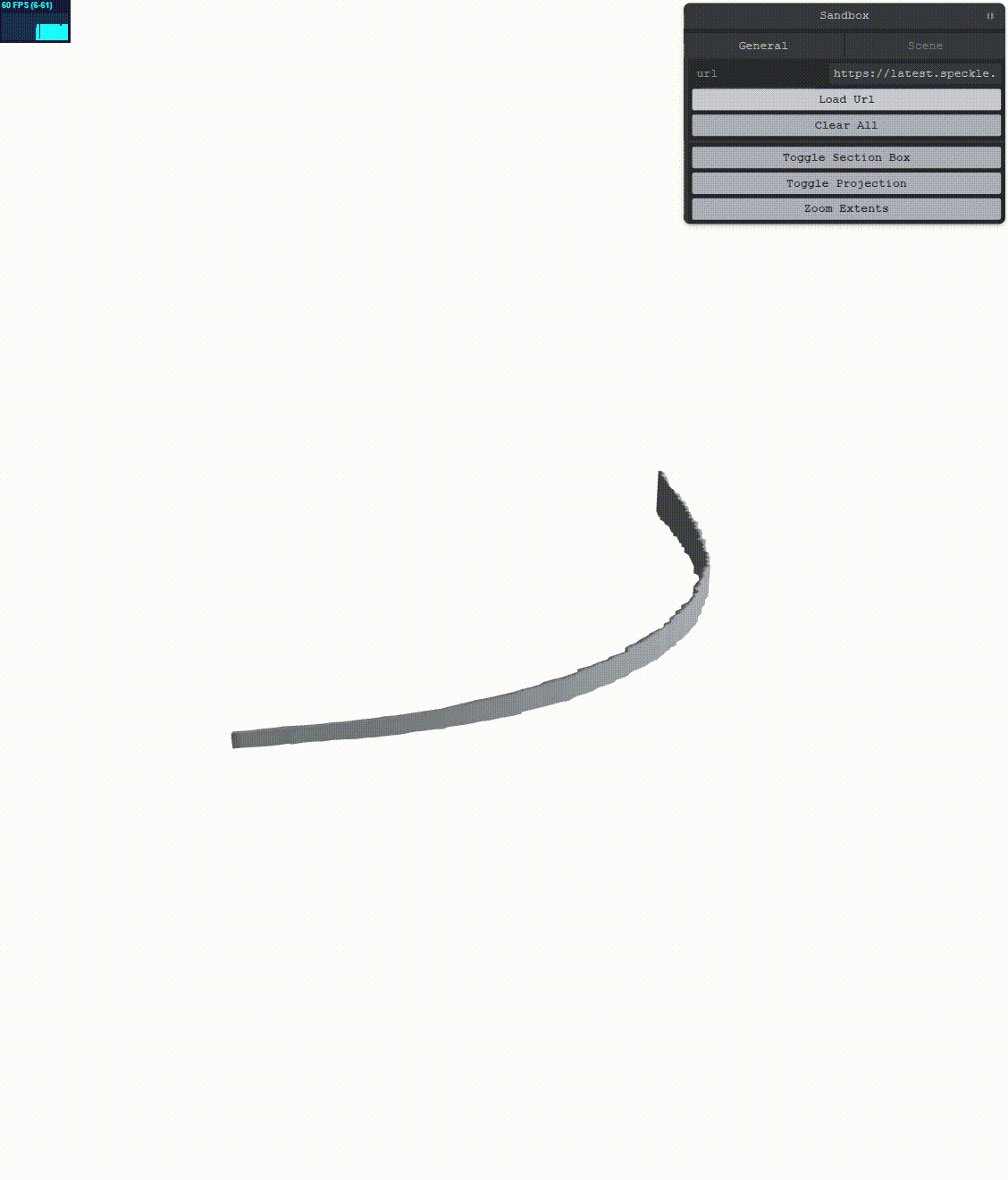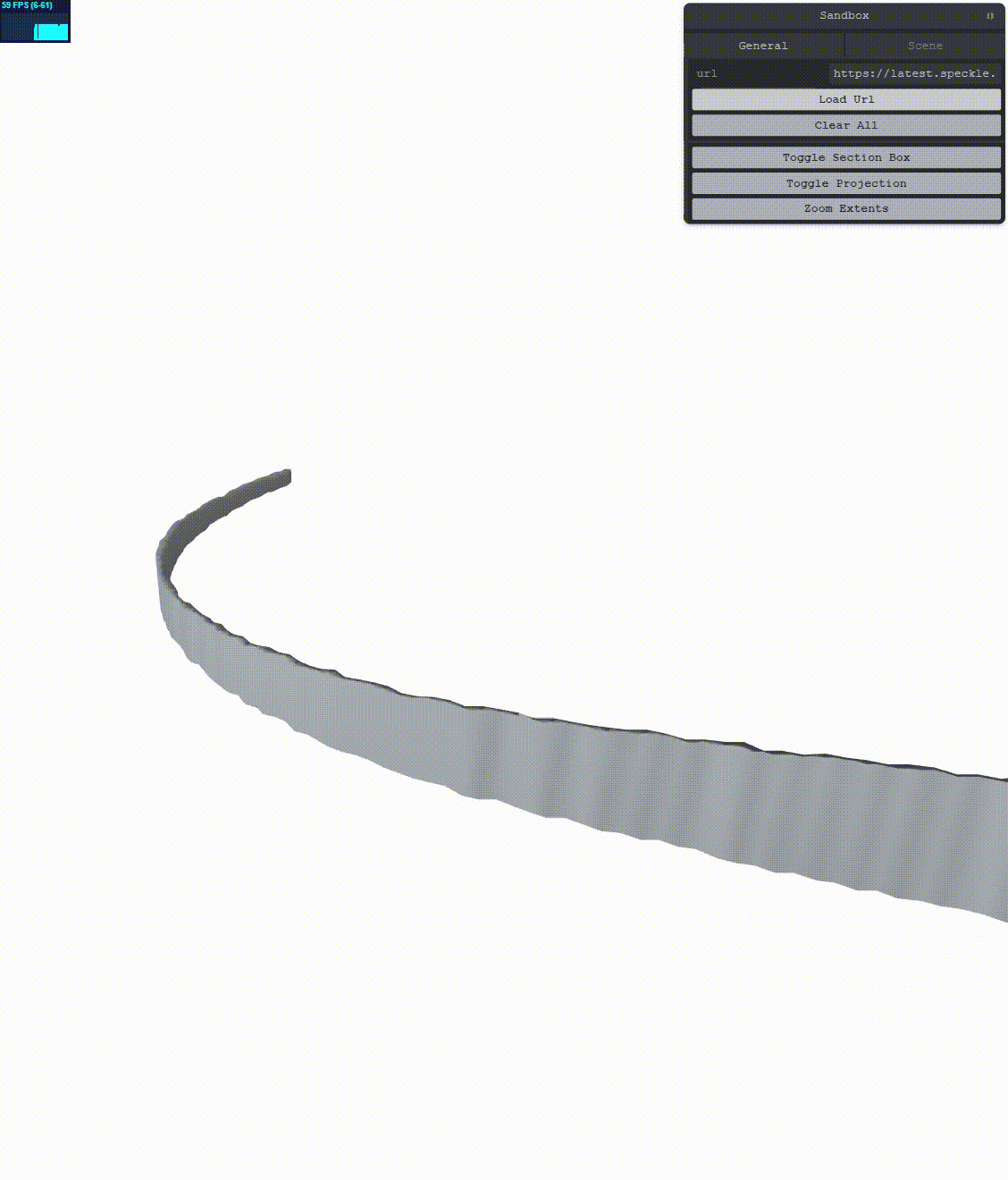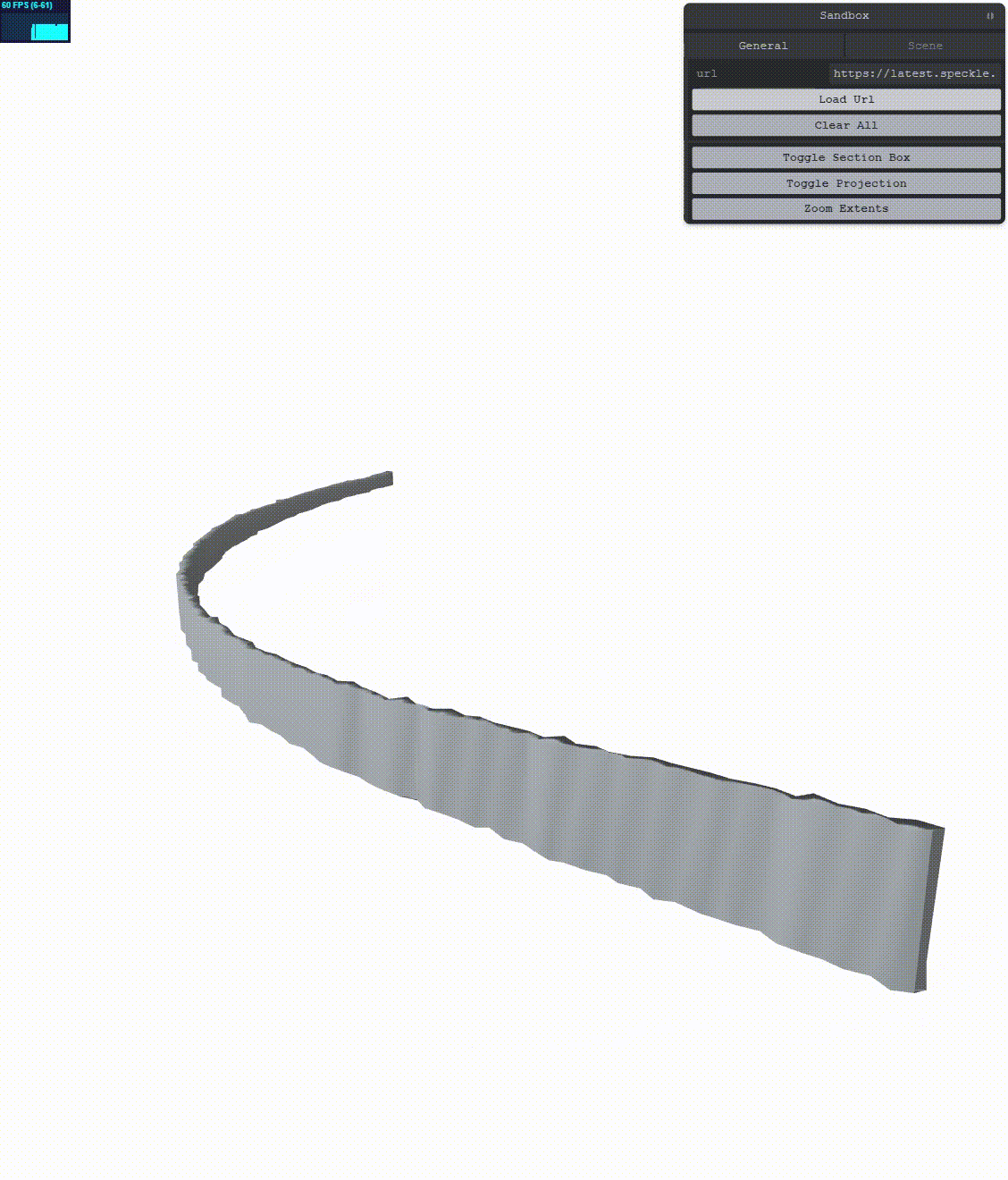
Now let’s use simple RTE. We need to change the vertex program from three’s stock to:
// Note: This is a simplification. I kept only what's relevant for example's sake.
// There's more stuff going on, but not relevant for this.
attribute vec3 position; // The vertex position attribute
uniform vec3 uViewer; // The camera position
// vec4 mvPosition = vec4(position.xyz, 1.); Three.js stock
vec4 mvPosition = vec4(position.xyz - uViewer.xyz, 1.) // RTE. Inverse translate the world
mvPosition = modelViewMatrix * mvPosition;
gl_Position = projectionMatrix * mvPosition;
Additionally, we need a modelView matrix that holds the viewer matrix at position 0,0,0. Remember, the camera is the world origin in RTE.
// Indices 12, 13, 14 hold the translation component
object.modelViewMatrix.elements[12] = 0
object.modelViewMatrix.elements[13] = 0
object.modelViewMatrix.elements[14] = 0
Let’s see what we get:
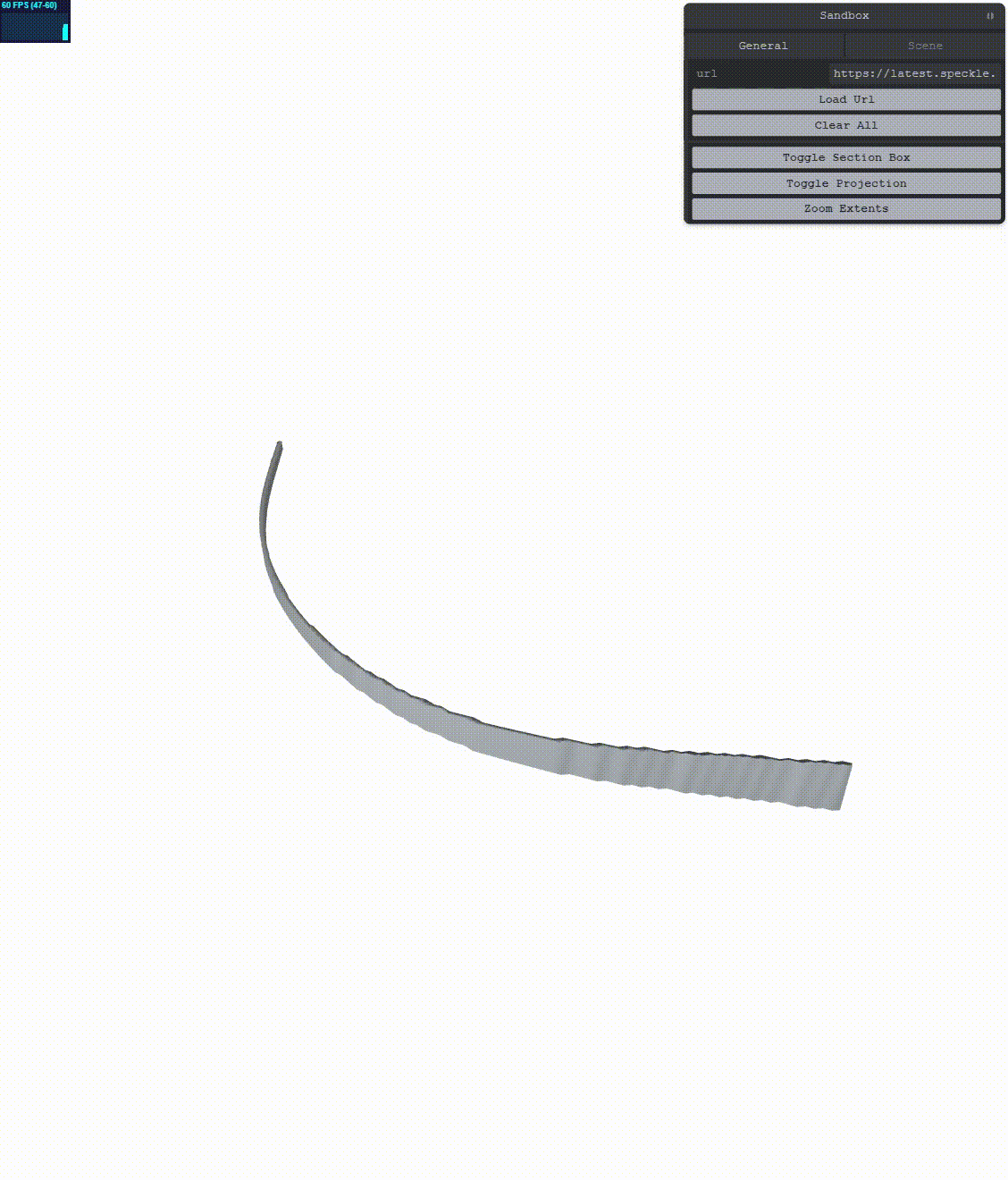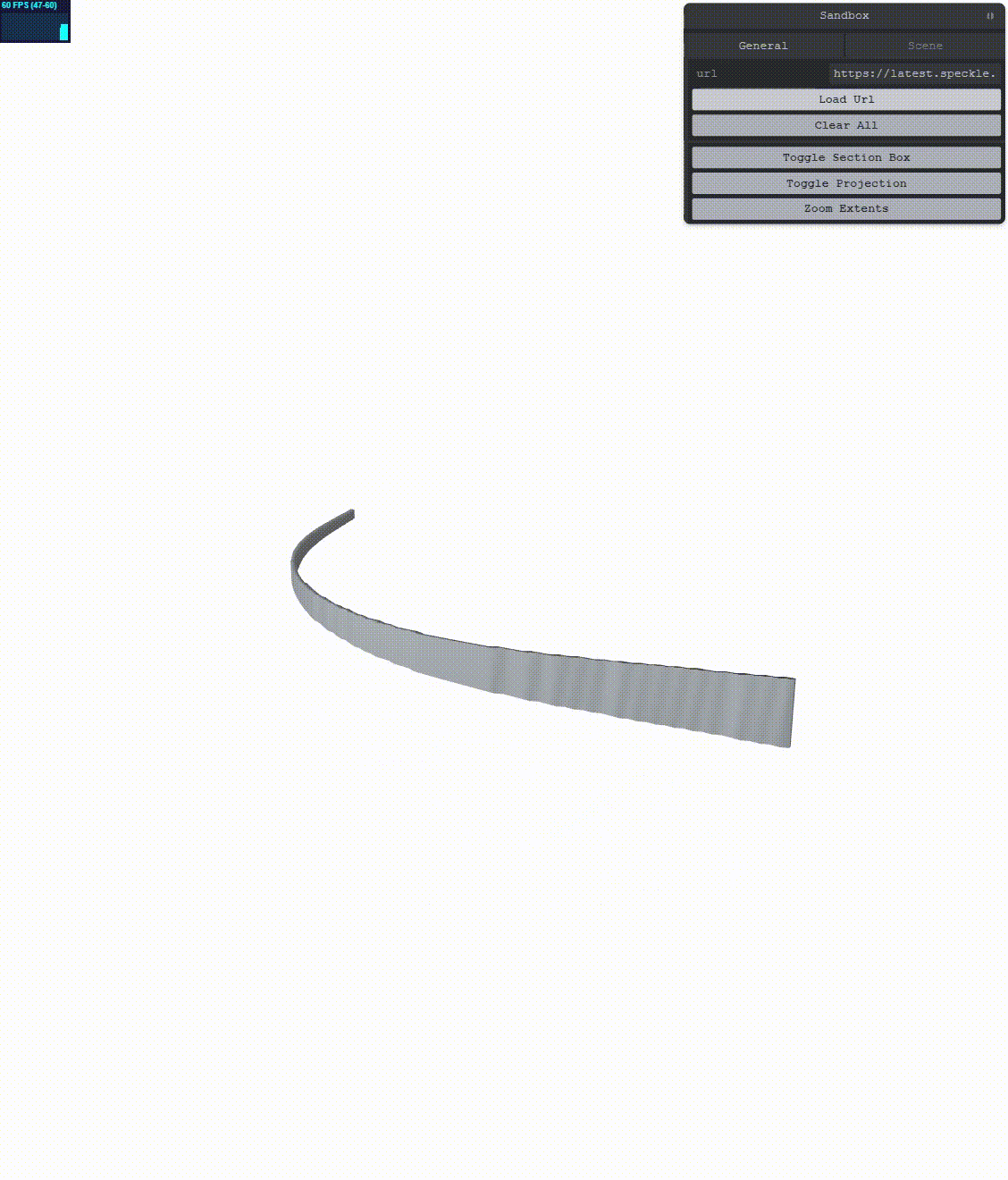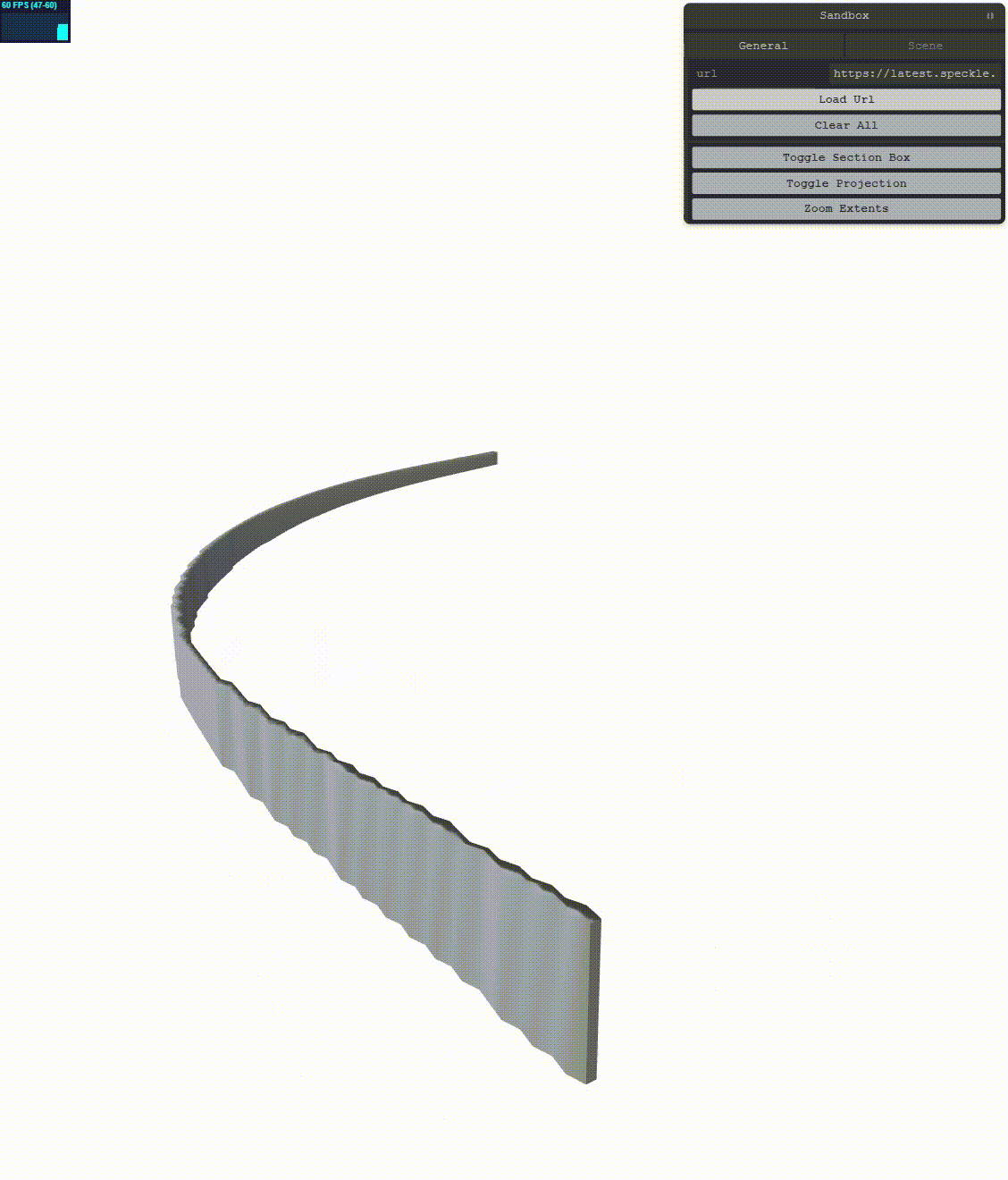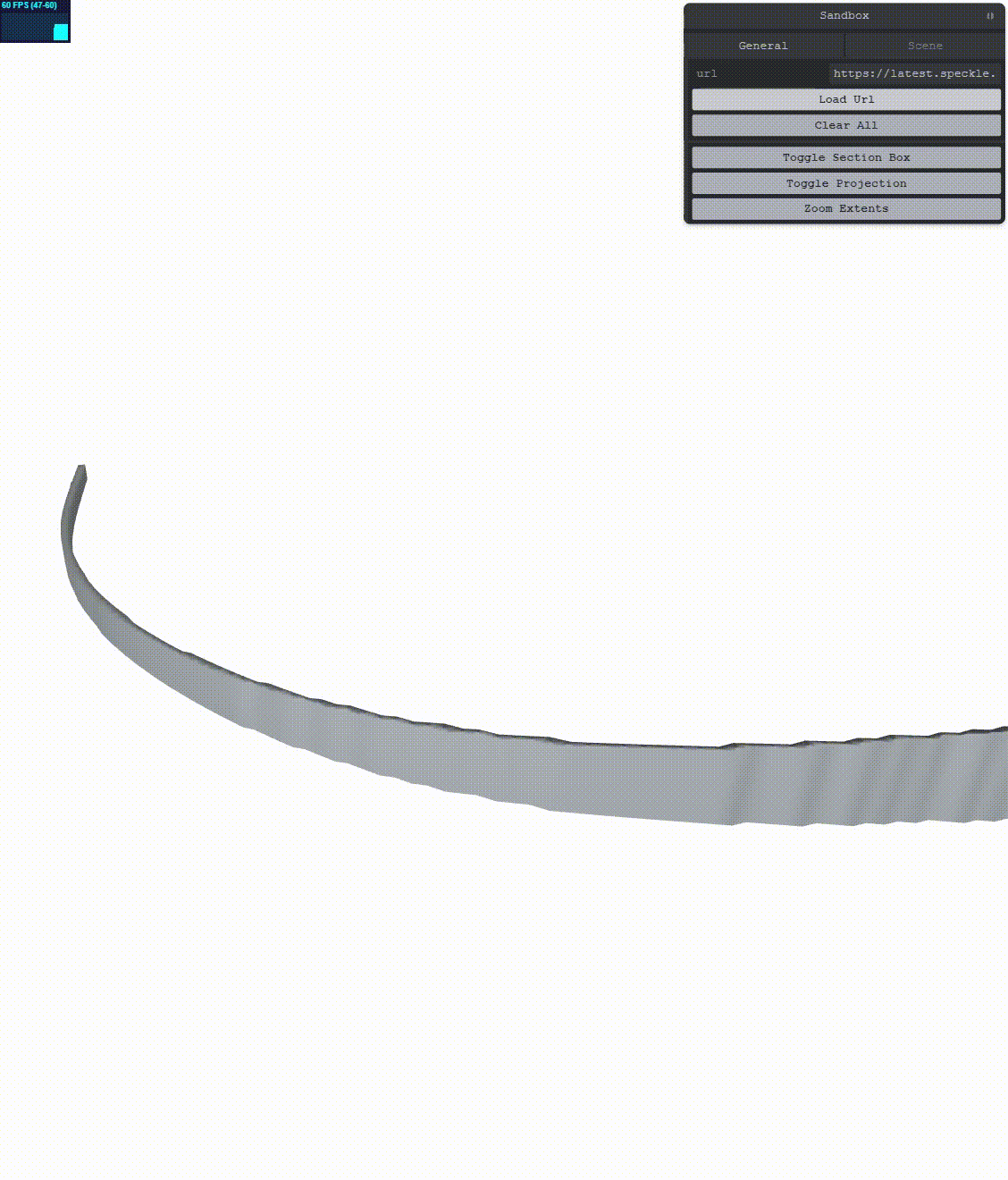
This results in less jitter, however, the jitter is not completely gone! We need to augment the simple RTE method. According to the main reference, we can go a bit further. We can increase the precision of our positions by encoding their double value into two floats. In order to do this, we’ll have to change more things.
First, we’ll need to split the position attribute into two separate attributes, low and high, corresponding to the two floats computed as per the article. We’ll also need to compute the camera position using two floats.
// Note: This is a simplification. I kept only what's relevant for example's sake.
// There's more stuff going on, but not relevant for this.
attribute vec3 position_low; // The vertex position low attribute
attribute vec3 position_high; // The vertex position high attribute
uniform vec3 uViewer_low; // The camera position low component
uniform vec3 uViewer_high; // The camera position high component
// vec4 mvPosition = vec4(position.xyz, 1.); Three.js stock
vec3 highDifference = vec3(position_high.xyz - uViewer_high);
vec3 lowDifference = vec3(position_low.xyz - uViewer_low);
vec4 mvPosition = vec4(highDifference.xyz + lowDifference.xyz , 1.);
mvPosition = modelViewMatrix * mvPosition;
gl_Position = projectionMatrix * mvPosition;
::: tip The Implementation ✨
:::
With this change we get:

The jitter is completely gone!
Takeaways
There is a slight downside to using the approach of encoding double values to two floats: you increase the memory footprint since you are using two vertex attributes for the position. The increase is not that large because the viewer uses relatively few vertex attributes in total: position, normal, UV, while typically a graphics application would use more attributes like a second UV set, and tangents.
The changes that come with this RTE implementation are universally functional. As in, the viewer renders correctly regardless if the world is large or small. However, RTE will work up to certain distance values. Besides maximum value, there is also the matter of accuracy, which can be increased by reducing the maximum value. We can tweak this if the need arises.
Here is another example of No RTE vs RTE in a more relatable scenario:

No RTE

RTE
What's Next?
Moving forward, we will try this change to RTE in order to see if there is any difference in accuracy/range - for better or for worse.
::: tip Check out Part 2 of our RTE exploration here
:::
Contributions Welcome!
Speckle is Open Source, and this includes our viewer! We are working towards creating a solid & performant 3D viewer that can reliably display geometry and associated metadata. If you want to contribute, and/or have better ideas and thoughts, we’d love to hear them. All our code is here:
 specklesystems
specklesystems