

The one about building stuff
Welcome back, this is the second part in our DevOps series. If you made the serious mistake of not reading the first post, head over here, before continuing with this one.
Recap
In the first post we’ve talked about some high level DevOps concepts and what they mean to us. In this article we’re going to deep dive into the topic of continuous integration.
What is continuous integration?
As with all things DevOps its a set of practices, clever automations, some tooling and a lot of whatever works for you™ . The main goal of continuous integration is (surprisingly) to continuously ensure the integrity of the developed application.
Its a mindset from developers that everyone needs to frequently commit to a central version control systems (git in our case) and only allow the automation systems to produce deliverable results.
It's been the way, that it's fine to go on working on code without committing anything for days, not to mention manually building production artifacts. But the need to rapidly and reliably build and deploy apps to production (luckily) forced a change.
These days we have on average ~20 commits per day pushed to the speckle-server repo. Not that more is better, but it shows that we do push our stuff on a regular basis. And on each of those commits our predefined (and constantly evolving) automations are executed.
Pull / merge requests
Most version control systems have a mechanism, that enables anyone to change the source code and send out a request to the maintainers code named please integrate my awesome changes to your app.
This is what commonly referred to as pull / merge requests.
This workflow enables configuring a certain set of criteria, to which the code proposed for integrating must adhere to. Our pull request workflow requires all of our CI jobs pass and requires a human code review, before merging any new changes to the main branch of our codebase. This way the we can always be sure that the integrity of main branch is intact at any given moment and we can take any snapshot of the app and deploy it to a live, publicly available environment.
This doesn’t ensure that our system is 100% bug free but its a good start and it allows us to very rapidly iterate and publish new versions of our app. Each of above mentioned 20 commits per day get deployed to our latest channel instances, but we’ll touch more on the topic of deployment in the next post.
CI workflow job categories
- a build / compile step ensures that the syntax of the code adheres to the language rules, produces reusable artifacts like distributable package formats. This step would build all the components of the codebase, producing artifacts, that may be deployed to a live environment.
- a testing step that runs automated test suites to ensure the code behaves as expected.
Note 'expected' as in expectations defined in test cases, not in the heads of people.- unit tests that validate the correctness of small units of the app
- integration test that check that the whole application, and its dependencies, like databases and external services etc. are functioning (well integrated) together.
- end 2 end tests that test the behavior of the whole application mostly focused on the users perspective
- analytics on the test results ie. code coverage and performance metrics
- code coherence and stylistic checks ie. linters and formatters
Our workflow
Let's dive in and take a look at how all of those concepts are implement in our Speckle server project. All of what its talked about is open source and available in the repo so you can follow along.
To start with the obvious, we are using GitHub as a centralized git server and we utilize the GitHub pull request workflow to tie together all the steps. We require that:
- all jobs of our CircleCI pass
- codecov coverage checks pass based on the test results of the CircleCI test job
- pre-commit.ci linting and formatting checks are green
- a pragmatic human code review approves and merges changes
Circle CI jobs
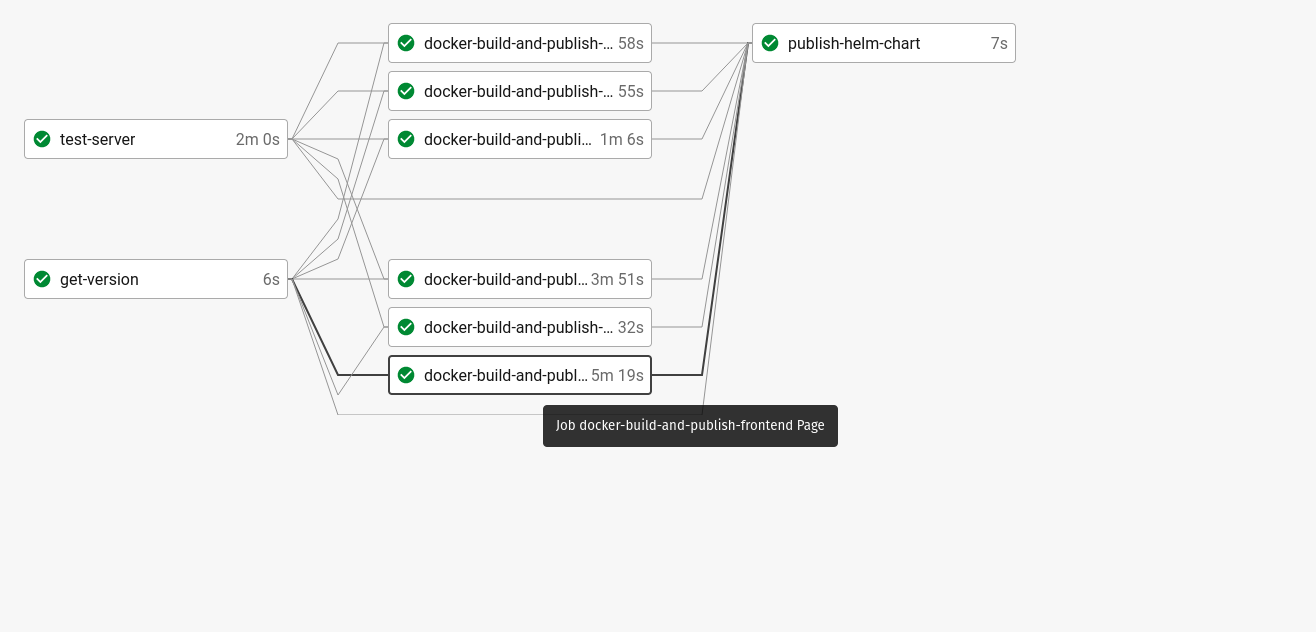
For each commit on a branch (may it be opened by a PR) our CircleCI workflow kicks in and it starts the workflow specified in the config file.
Recently we’ve reworked the configuration in a way, that it breaks down the whole build process into separate single focused jobs:
- set up the current version of the whole artifact bundle
- run the test suite of the server
- circuit breaker: stop if not main branch
- slight pragmatic shortcut we take the steps below are fit only run on commits to the main branch.
- build all the docker container artifacts and publish them to docker hub with the common version number
- publish a new helm chart with the common version number
- circuit breaker: stop if not triggered by a release git tag
- another pragmatic shortcut, the steps below are filtered to only run,
- publish npm packages to the public npm registry
The two circuit breakers in the job definitions are slight pragmatic shortcuts, that we take:
- At the moment we do not deploy feature specific instances, so time spent on building docker containers for commits not on the
mainbranch would slow down the feedback cycle of the test results, but this could change in the future, when we have the need for feature specific test environments. - The npm publish stage is only ran whenever we’re making a stable release (more on the release channels in the next post), but again this might change in the future if have the need to publish and test canary npm packages.
The way these jobs are implemented in CircleCI take advantage of a flexible runtime dependency graph resolution between the different jobs. With our current job dependency graph all the docker containers are built in independent jobs and the frontend container build is not dependent on the server tests. This made our full build pipeline ~2.5x faster than it was before, where we ran all of these steps sequentially one after the other.
Codecov checks
The completion of the test server job in circle ci triggers a check executed on codecov.io, that ensures that the server codebase test coverage is above a certain set threshold and the coverage percentage doesn’t decrease after merging the given pull request. Having test coverage checks doesn’t save us from bugs or badly written tests, but at the very least it puts us into a mindset of we cannot put anything into production without writing tests for the functionality.
Pre-commit CI
With the ever increasing number of people committing code to the speckle server codebase it gets harder and harder to keep a consistent coding style, so we recently added some safeguards for it. We utilize pre-commit and pre-commit.ci which gives us a very easy to use, extensible and quick check system. For now we are using eslint for linting each of the package codebases and prettier to format the code to a consistent style.
Building the helm chart
To be able to utilize helm when deploying to Kubernetes, we need to maintain our own helm chart repository. It sounds mysterious but it is just a collection of simple structured of yaml files, that should be accessible on a public url. The repo itself can be accessed from https://specklesystems.github.io/helm/
Our circle ci helm publish step updates the helm chart in https://github.com/specklesystems/helm git repository with the newly built version number. The chart repo has an independent Github Action CI step configured, that utilizes a reusable helm chart releaser to update the helm repository to mark the availability of a new chart version.
Stable releases
We use GitHub releases to track the release history. Whenever we make a new release in GitHub, it creates a new git tag with the release version. The publication of a new semver version tag triggers a new run in our CI system, that will build the release specific artifacts.
Artifacts we publish
When all the steps are complete, the following final artifacts are published:
- a tagged release with generated changelog at https://github.com/specklesystems/speckle-server/releases
- docker containers for each service in the server, found in our docker hub registry: https://hub.docker.com/u/speckle
- an updated helm chart available from https://specklesystems.github.io/helm/
- npm packages https://www.npmjs.com/search?q=keywords:speckle
Wrap
This marks the end of the overview of our CI strategies. Next up we’ll discuss our deployment pipeline. Thanks for reading, here's a 🥔