Aug 4, 2025
Speckle's Improved Ambient Occlusion: A Closer Look
Ambient Occlusion inside the Speckle Viewer
The Speckle viewer has two different ambient occlusion (AO) methods for dynamic and stationary scenarios. The dynamic AO applies whenever the camera or objects are moving, while the stationary AO activates when everything is still — meaning the camera and scene objects aren’t moving. Both methods share some ideas, like being computed in screen space, but they are distinct. This section will explain both, focusing mainly on the stationary ambient occlusion.
First, take a look at the model below to see the final result. Try zooming and rotating, then stopping to notice the difference between the progressive and dynamic ambient occlusion modes.
Dynamic Ambient Occlusion
Our dynamic AO implementation is similar to ThreeJS’s SAO (Screen Space Ambient Occlusion) based on Alchemy AO, but with a slightly different approach. Unlike ThreeJS, which uses an extra pass to generate normals, we reconstruct view-space normals on the fly from depth. This is because passing all geometry through the GPU multiple times was too slow for typical Speckle streams. We started from ideas like this approach and improved it with the method described here. Both implementations still exist in our codebase behind conditional compilation.
Reconstructing normals on the fly also helps fix AO artifacts caused by incorrect vertex normals.

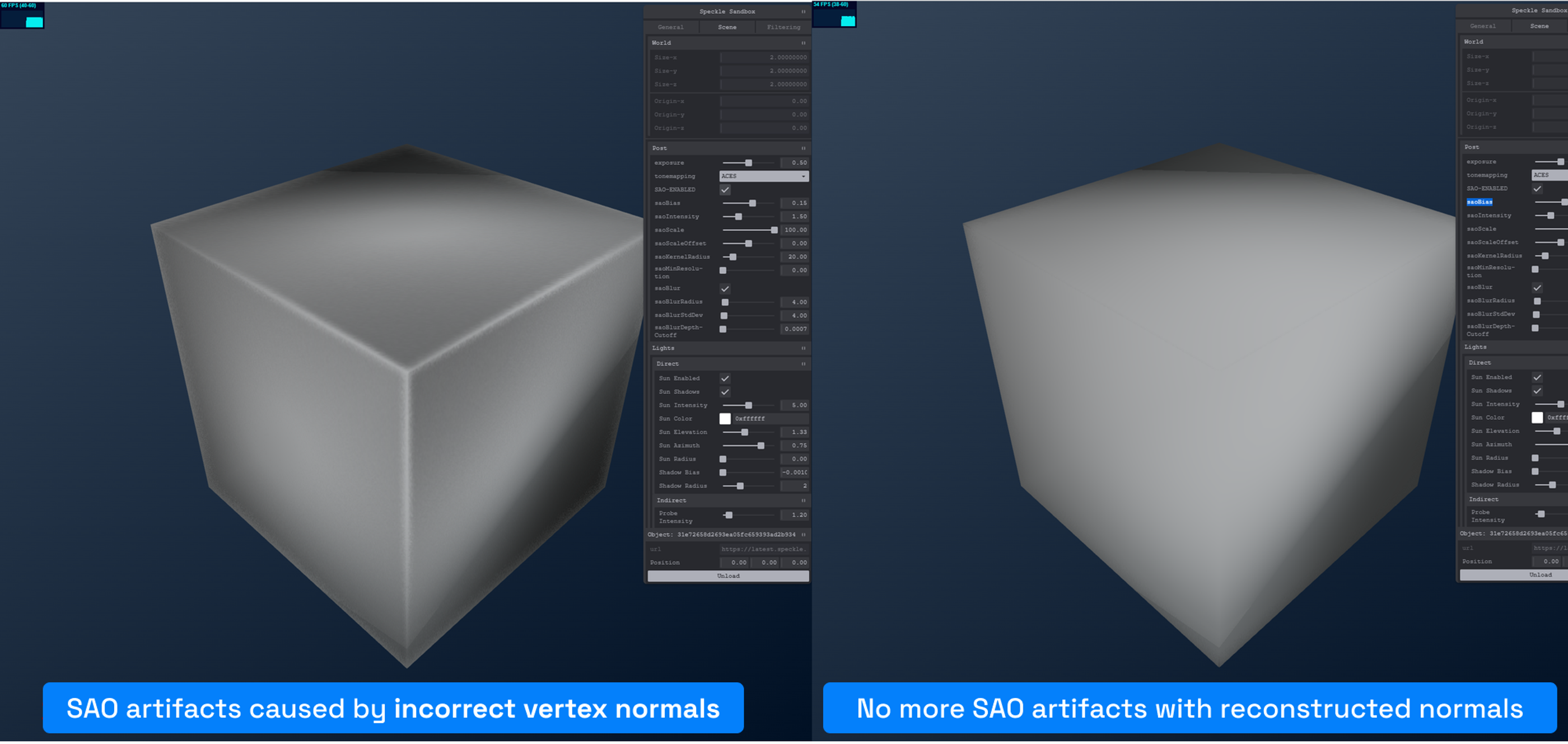
After testing, reconstructing normals this way proved faster than rendering vertex normals in a separate pass for typical Speckle data.
Apart from that, our dynamic AO mostly follows the standard ThreeJS implementation. Here’s an example scene showcasing how it looks.

Stationary, Progressive Ambient Occlusion
After implementing dynamic AO, we wanted to improve quality further. SAO is decent, but it tends to be noisy or blurry unless you increase samples drastically, which hurts performance.
The challenge with screen space AO is that increasing the area around each pixel to sample requires many more texture fetches, slowing things down. Since the Speckle viewer needs to perform well everywhere, we couldn’t just increase sample counts for dynamic AO.
So, we asked: can we trade spatial sampling for temporal sampling? Instead of many samples in one frame, we take fewer samples per frame over multiple frames and accumulate results progressively. This idea led to our progressive AO.
We explored three AO algorithms to see which worked best:
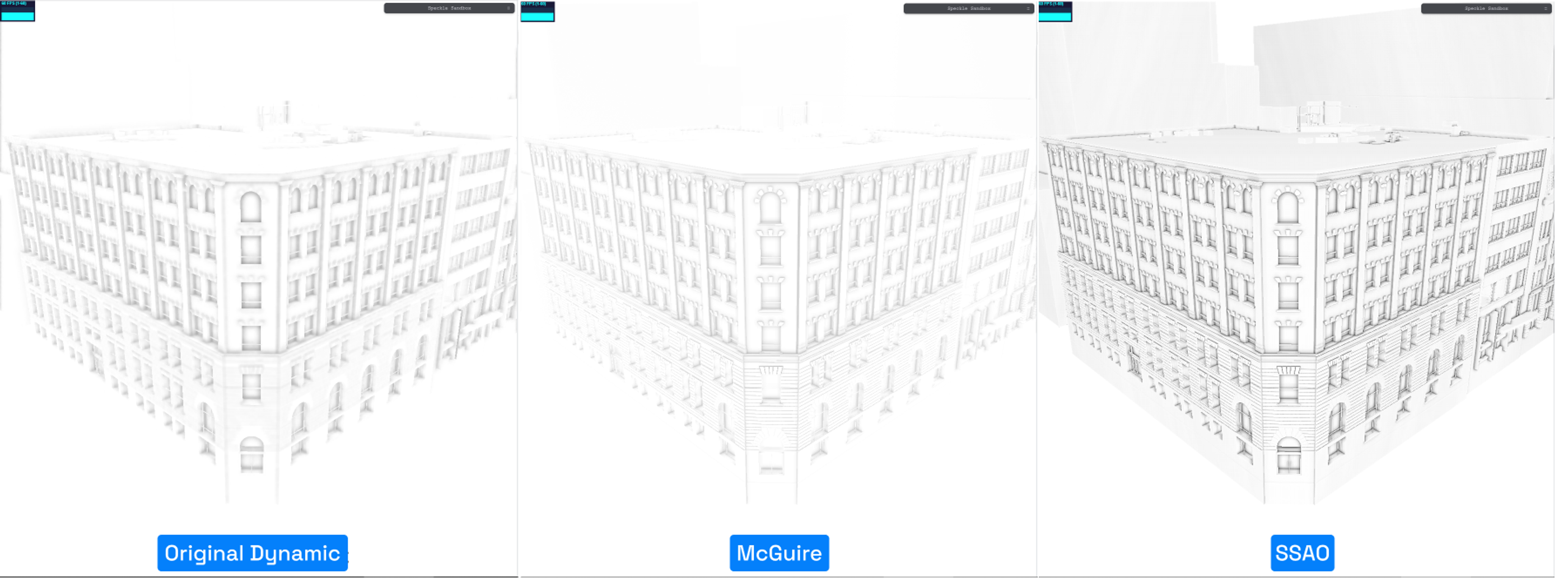
- Stock ThreeJS SAO estimator (based on McGuire’s method)
- The original McGuire estimator
- SSAO (Screen Space Ambient Occlusion) with uniform hemisphere samples and actual depth comparisons
To generate samples across frames, the first two algorithms use a spiral-shaped kernel (like the one shown below).
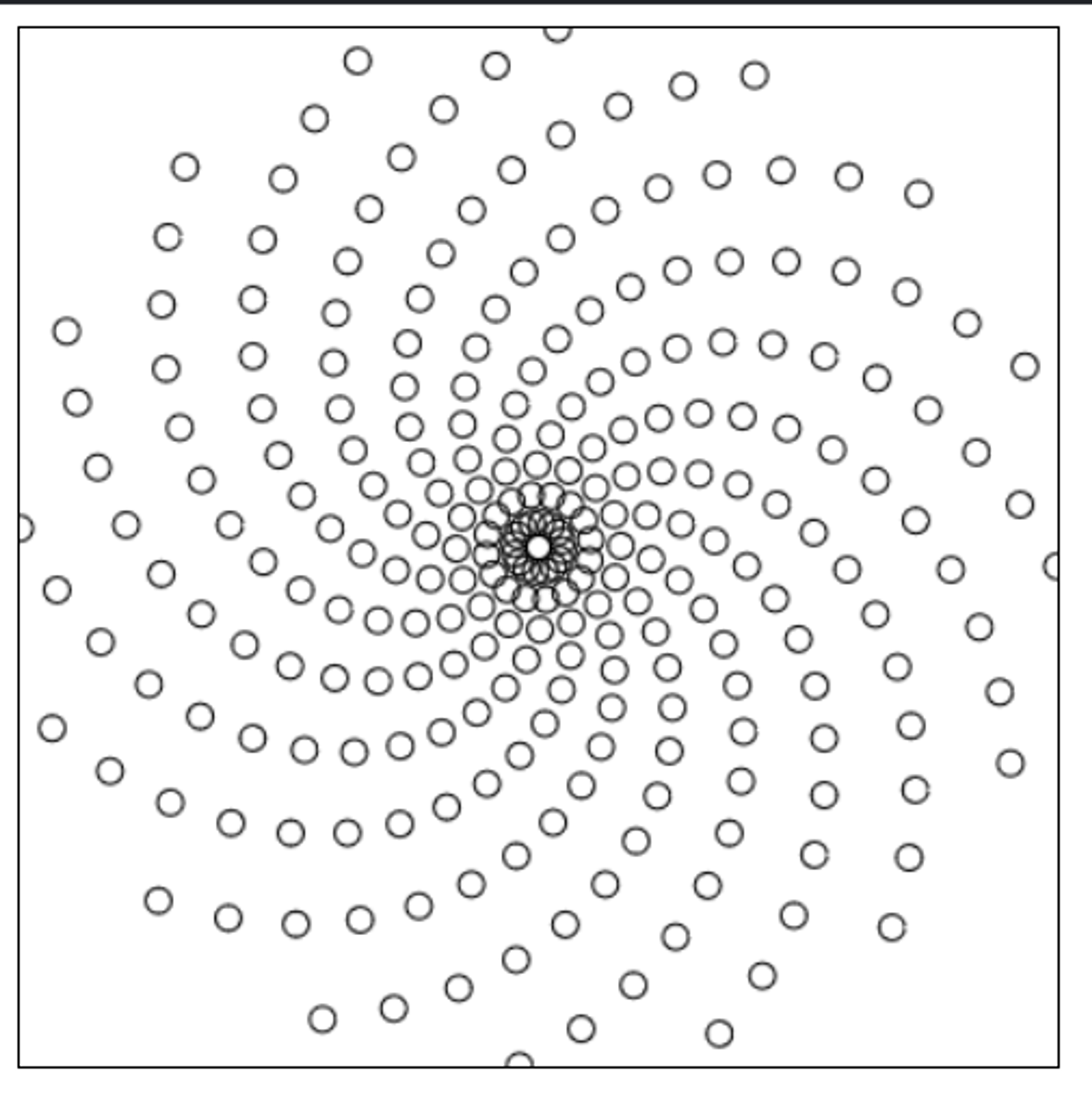
For SSAO, samples are generated randomly on a hemisphere, scaled by kernel size. This may not be optimal but was a straightforward starting point.
Each frame, we compute AO values using the current frame's samples, then accumulate them in a buffer holding previous frames’ data. The viewer typically takes 16 AO samples per fragment over 16 frames, but these numbers are configurable.
We generate AO in a "generation stage" where values are stored as white (non-inverted AO) and scaled by the inverse kernel size. Then, in the "accumulation stage," these values are blended into a buffer with a reverse subtract blending mode to invert the AO automatically. The buffer clears every accumulation cycle, and blending averages over the total frames.
After comparison, the McGuire estimator and SSAO were close, but the original McGuire method performed slightly better. We focused on comparing McGuire and SSAO with the dynamic SAO for reference.
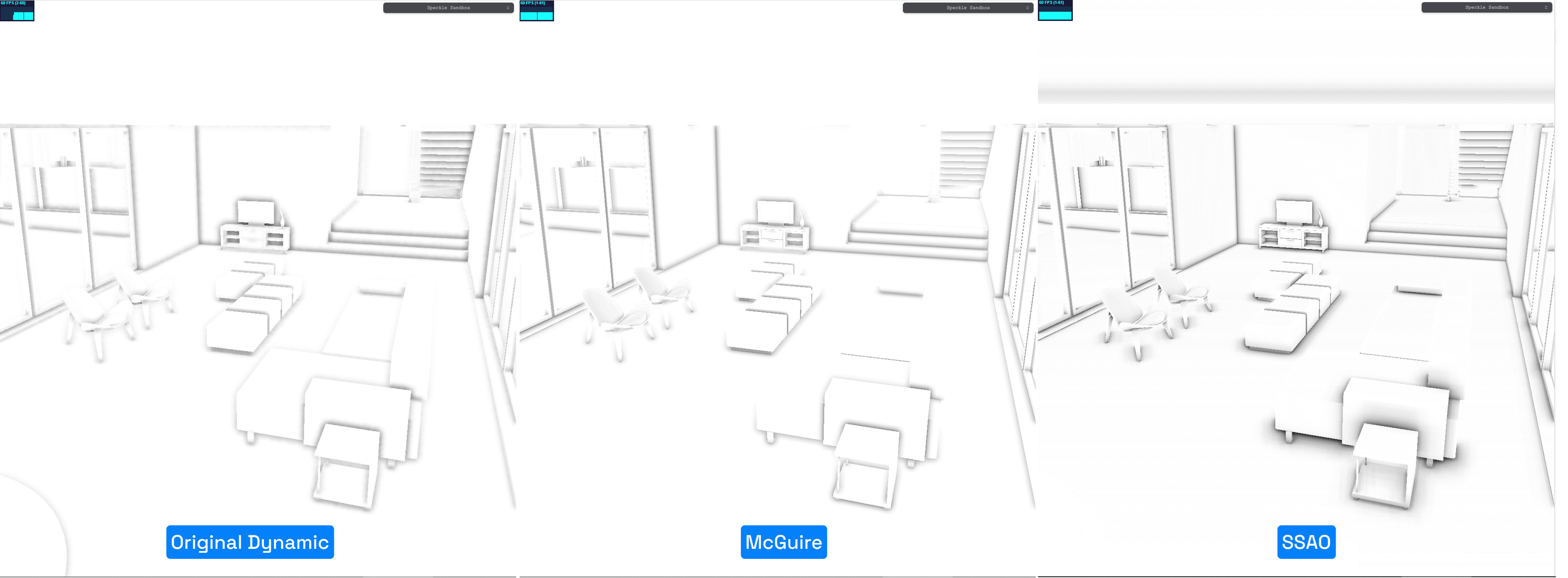
Comparison images - 1

Comparison images - 2
Comparison images - 3
Main differences: McGuire uses an estimator loosely based on pixel surroundings, while SSAO samples and compares depth in neighborhoods for more exact occlusion.
Interestingly, dynamic AO looks quite similar to progressive McGuire AO despite very different sample counts, which somewhat defeats the purpose of progressive AO.
To better evaluate, we compared these algorithms to Blender’s Eevee ambient occlusion, which is also screen space based.
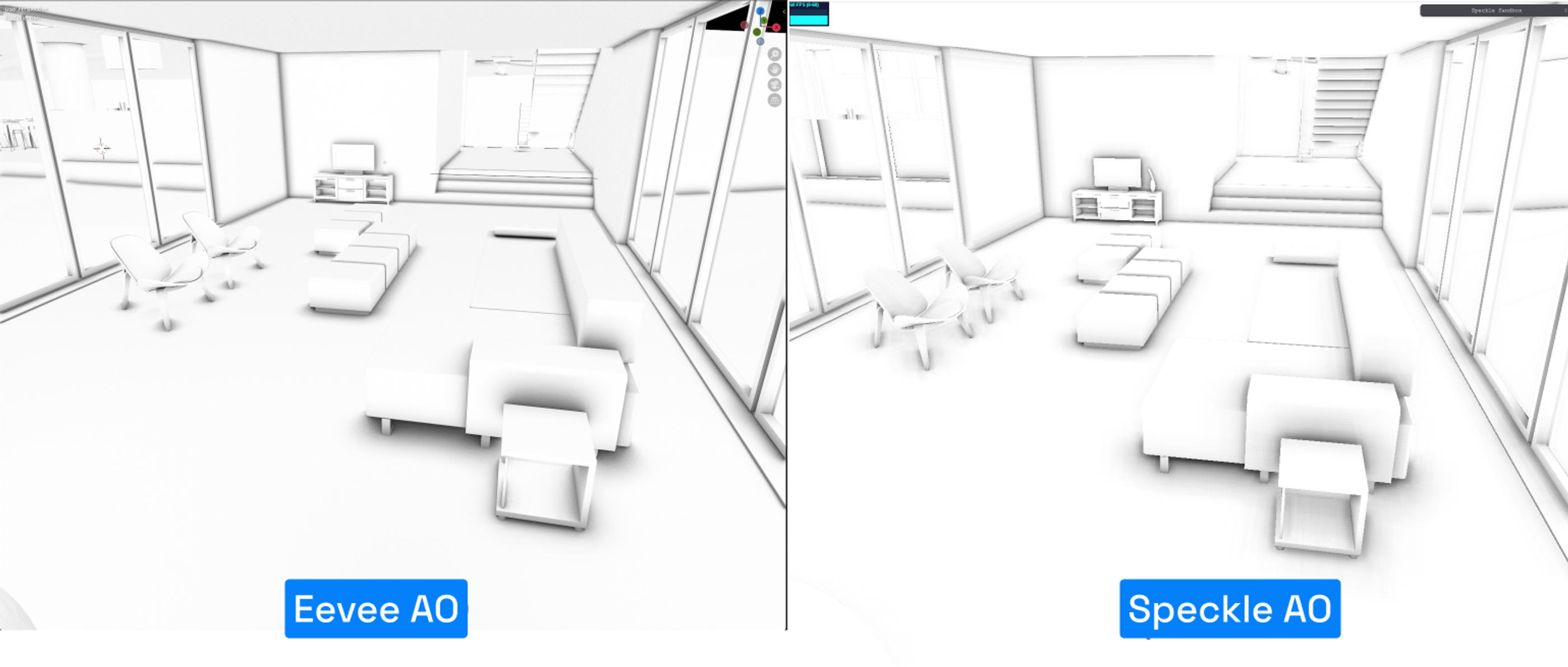
Eevee AO vs Speckle AO
The similarity gave us confidence to select SSAO for our progressive AO implementation.
Depth Buffer Challenges
While developing progressive AO, we found some strange artifacts visible only on macOS.
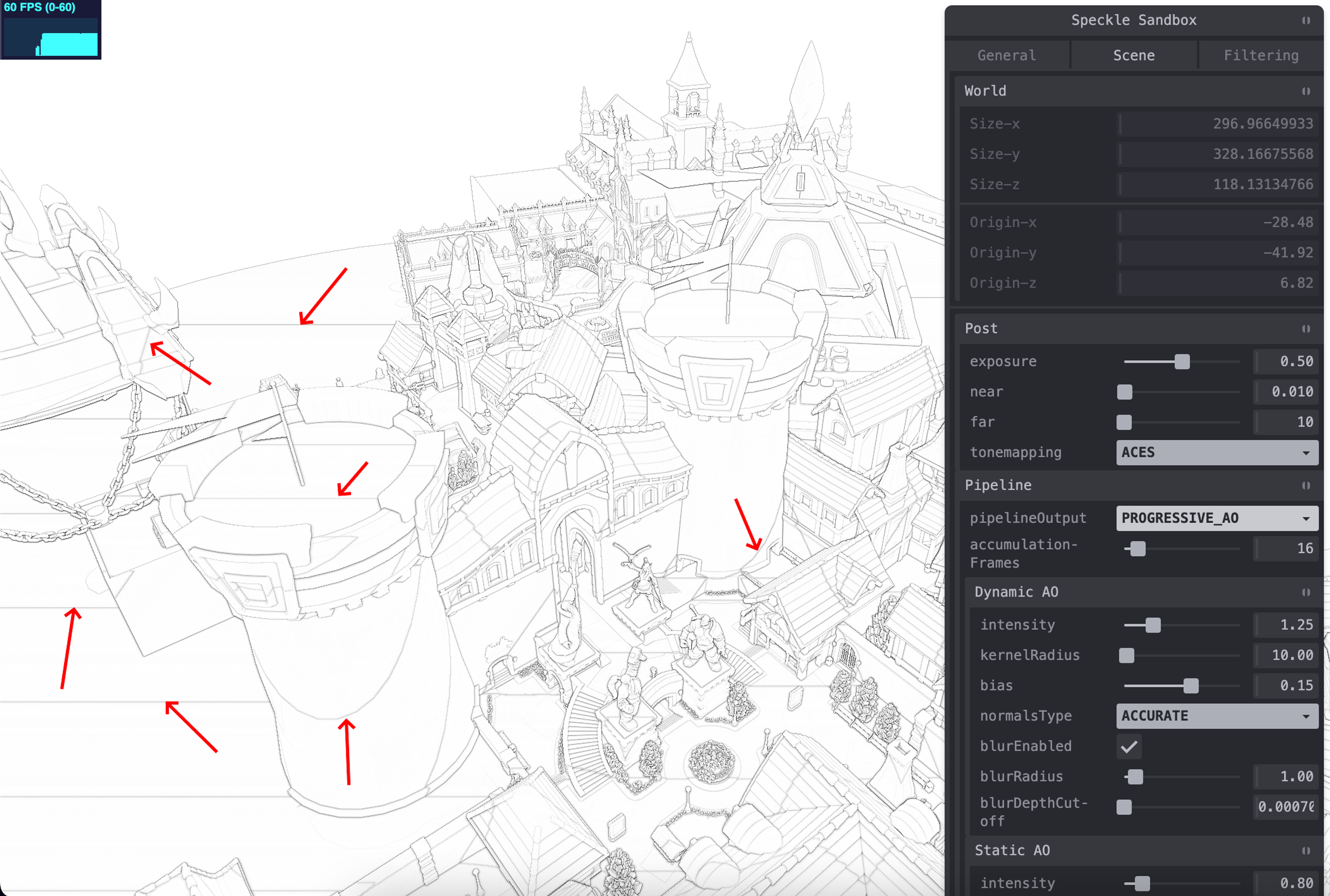
speckle-sandbox-progressive AO
We encode fragment depth as RGBA in an 8-bit texture for bandwidth efficiency instead of a float32 texture. This is standard in ThreeJS and shouldn’t cause issues. Biasing depth samples didn’t fix the artifacts either.
After trying different encoding methods and hardware depth textures, the solution was to output linear depth instead of perspective depth in the depth pass. This change eliminated artifacts with a small bias applied.
Variable Screen Space Kernel Size
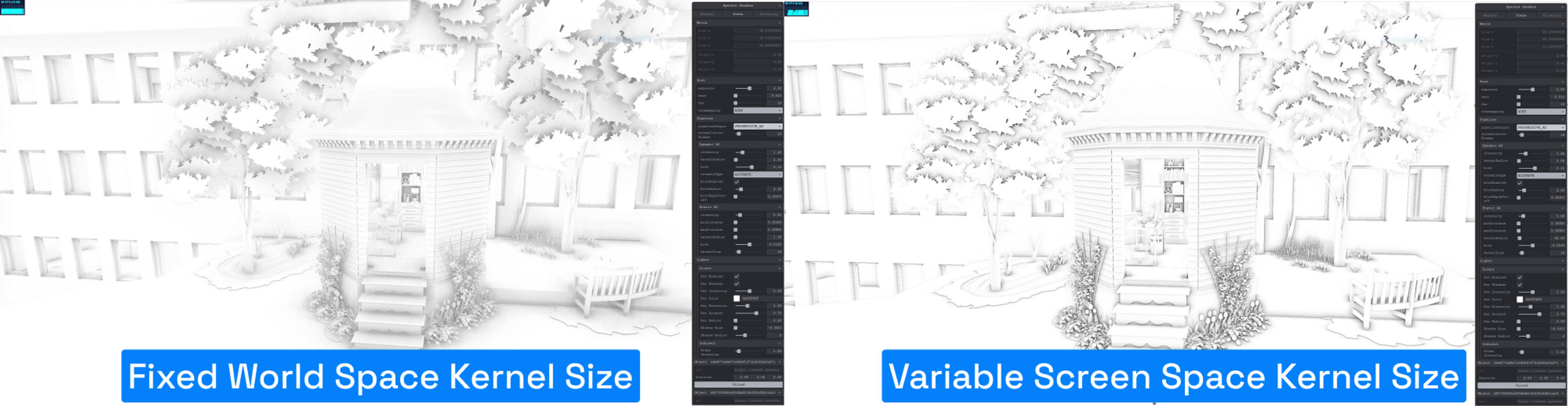
Most screen space AO implementations use a fixed kernel size uniform. This works when you know scene scale, but with Speckle, we can have scenes ranging from millimeters to kilometers—even both scales in one scene!
A fixed kernel size leads to inconsistent results, especially when loading streams of different sizes or zooming out the camera.
The original SSAO we used defines kernel size in world space, causing problems when scene scale varies.
Our solution: switch to screen-space kernel size, computed on-the-fly in the shader based on fragment view depth. We derived this from this formula, inverted to suit our needs.
Here’s an example comparing small and large scale streams:
space kernel
And another showing zooming out problems with fixed kernel size:
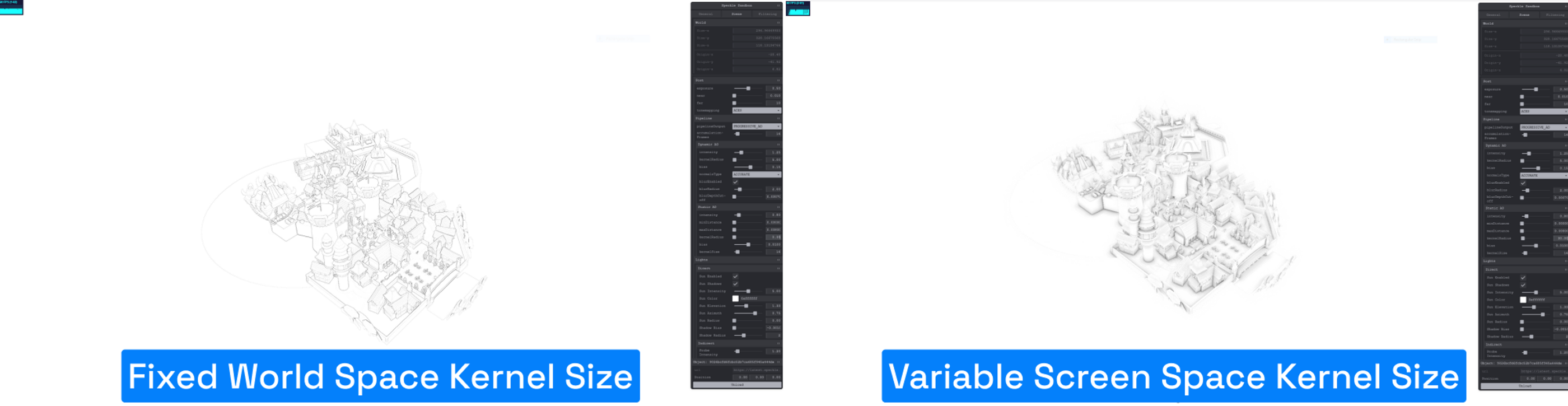
space kernel size - 2
Future Development
Our current progressive AO generation is simple and effective but could be improved with more advanced algorithms or better sample biasing to reduce samples needed.
We’re also interested in accelerating AO generation using hierarchical depth buffers, though current WebGL limitations restrict full implementation. Partial solutions might still help speed things up.
References

Alexandru Popovici
Graphics Engineer