How Suffolk Construction operationalizes design data with Speckle
Company
Founded in 1982 and headquartered in Boston, Suffolk Construction is a leading US contractor delivering complex projects across commercial, healthcare, and infrastructure sectors. Over the years, the company has built a reputation for leaning into technology early, especially where it can improve delivery speed, reduce risk, and give teams a real edge in how they work.
Murat Melek, Director of Design AI, and David Morgan, BIM Data Engineer, have contributed to that effort. Their focus is simple in principle but difficult in practice: make design data actually usable across the business, especially for the teams responsible for estimating, planning, and delivering projects.
Challenge
Every project starts with fragmented inputs. Architects, engineers, and subcontractors all model differently, using their own parameters, categories, and naming conventions.
In theory, BIM models contain everything needed for estimation and planning. In reality, getting that data into a usable form takes a lot of manual effort.
That gap has real consequences. Estimators spend time cleaning and reshaping data instead of analyzing it. Inconsistent inputs increase the risk of pricing errors and change orders. Decisions slow down because no one fully trusts that they’re looking at a complete, consistent picture. And it’s worth noting that these decisions don’t happen in sequence, which adds another level of complexity to this system.
Even something as straightforward as pricing a room becomes complicated. Walls, finishes, and elements might all be modeled differently depending on who created them, but the estimator still needs a single, consistent cost code. The data just isn’t set up to support that.
In Suffolk’s case, their team wasn’t typically building the models, so they had limited access and context needed to understand how the models worked in Revit. They were extracting and analyzing data from the model.
Solution
To solve this, Suffolk built a centralized data lake focused on construction data. Before Speckle, they lacked visibility into and access to this data, which made it difficult to integrate into their system. With Speckle, they were able to smoothly bring this data into their data lake. In effect, Speckle acts as a pre-construction data layer that connects to their Databricks lake.
Instead of working directly with fragmented BIM files, teams push data from their authoring tools and Autodesk Construction Cloud into Speckle. There, it’s normalized, structured, and prepared for downstream use.
We have our modeling tools and ACC, and we're doing all this authoring, but how do we extract and clean the data? We push it into Speckle, making it accessible upstream for construction. That's our data lake system that helps process data and maintain clean business logic.

David Morgan
BIM Data Engineer

This changes the role of BIM data entirely. Instead of being something you extract from when needed, it becomes part of an ongoing system, something that can be accessed consistently, reused across workflows, and trusted when decisions need to be made.
How they did it
Suffolk’s approach is built around four components: the building data lake, ACC-to-Speckle sync, event-driven automations, and the building data pipeline.
ACC To Speckle Sync
By setting up an automated bridge with Autodesk Construction Cloud, models are synced and transformed as they’re updated. Instead of relying on manual handoffs or file exchanges, the data lake reflects the live state of the project. That removes a lot of friction and avoids the typical “walled garden” problem where data gets stuck in one system.
The Building Data Lake
Speckle converts complex BIM files into a queryable relational database accessible via standard APIs. In practice, this means data that used to live inside siloed tools becomes something teams can actually query, connect to, and use. It also opens things up significantly because the data is no longer tied to authoring tools; the data team can work with it without needing Revit licenses or specialized software.
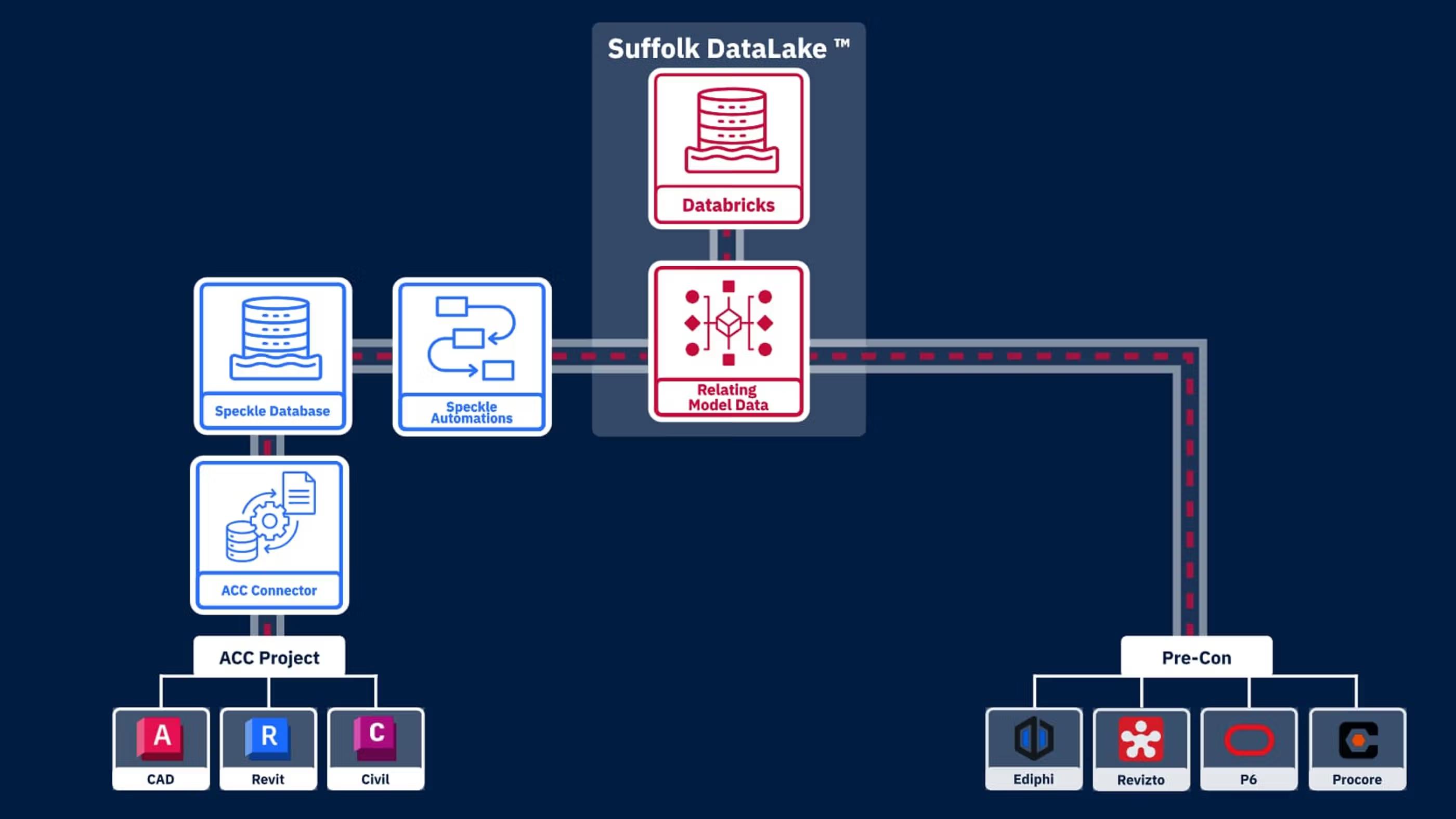
Event Driven Automations
Every time a new model version is committed, automated functions run health checks and classify the data. This shifts quality control earlier in the process. Rather than catching issues downstream, the system ensures only clean, structured data moves forward, reducing rework later.
The Building Data Pipeline
All of this feeds into the building data pipeline. Instead of building custom scripts or processes for each project, Suffolk has created a repeatable system that automatically handles tasks such as structural pattern matching and material quantity extraction. The pipeline maps design data directly to Suffolk’s internal schemas, so outputs remain consistent across projects and workflows as estimation scales.
We use Speckle Automate, and the AI algorithm is pretty much deciding, ‘Hey, based on what I see here, the closest matching code is xyz,’ so that we can programmatically move the data to estimation.

Murat Melek
Senior Director, Design AI
The day-to-day workflow looks very different as a result. Instead of exporting model data, cleaning it manually, and rebuilding it in spreadsheets, the data flows automatically from ACC into Speckle, gets structured in the data lake, is enriched through automation, and then moves directly into estimation systems with consistent cost coding.
Results
This shift from manual workflows to a structured data pipeline changes how projects are actually delivered.
Estimators can move faster because they’re starting with clean, structured data instead of raw inputs that need to be fixed. That means less time spent preparing data and more time focused on analysis and decision-making.
There’s also a noticeable improvement in consistency. With standardized data feeding into estimation, the risk of errors caused by mismatched inputs goes down, which leads to more reliable pricing and fewer downstream corrections.
Manual handling is reduced across the board. Instead of repeated copy-paste workflows and one-off scripts, teams rely on a system that automatically prepares and routes data.
At the same time, access to BIM data broadens. Estimators, planners, and project managers no longer have to rely on static PDFs or indirect summaries; they can work directly with structured model data. That leads to faster decisions and better coordination between teams.
Over time, the impact compounds. Because the data is consistently structured and stored, each project adds to a growing pool of usable information. Model elements are automatically classified and mapped to cost codes, which allows estimation workflows to run with minimal manual input.
This also opens the door to learning across projects. Patterns that were previously hard to see, like recurring design issues, can now be identified earlier. Instead of reacting to problems on site, teams can start catching them during design and planning.
What used to be an isolated project data becomes something much more valuable: a shared, evolving dataset that improves performance across the entire portfolio.
Future
Suffolk is continuing to build on this foundation, expanding its data pipeline and automation capabilities across more projects and workflows.
The focus now is on scaling what’s already working, embedding structured data deeper into estimation and planning, and increasing the use of AI-driven workflows that rely on consistent, high-quality data.





